What is buffer overflow?
Buffer overflow is an anomaly that occurs when software writing data to a buffer overflows its capacity, causing adjacent memory locations to be overwritten. In other words, too much information is passed to a container that does not have enough space, and that information ends up replacing the data in adjacent containers.
Buffer overflows can be exploited by attackers to modify a computer’s memory in order to undermine or take control of program execution.
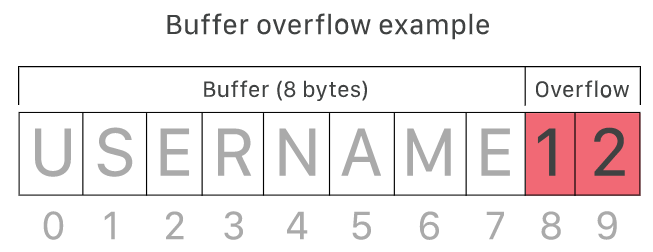
What is a buffer?
A buffer, or data buffer, is an area of physical memory storage used to temporarily store data while it is being moved from one place to another. These buffers are usually located in RAM. Computers frequently use buffers to help improve performance; most modern hard drives take advantage of buffering to access data efficiently, and many online services also use buffers. For example, buffers are frequently used in online video streaming to prevent interruptions. When streaming a video, the video player downloads and stores perhaps 20% of the video at a time in a buffer and then streams from that buffer. This way, small drops in connection speed or quick service interruptions will not affect the performance of the video stream.
Buffers are designed to hold specific amounts of data. Unless the program using the buffer has built-in instructions to discard data when too much is sent to the buffer, the program will overwrite data in the memory adjacent to the buffer.
Buffer overflows can be exploited by attackers to corrupt software.
Despite being well known, buffer overflow attacks remain a significant security issue that plagues cybersecurity teams. In 2014, a threat known as “heartbleed” exposed hundreds of millions of users to attack due to a buffer overflow vulnerability in SSL software.
How do attackers exploit buffer overflows?
An attacker can deliberately introduce a carefully crafted input into a program that will cause it to attempt to store that input in a buffer that is not large enough, overwriting parts of memory connected to the buffer space. If the program’s memory layout is well defined, the attacker can deliberately overwrite areas known to contain executable code. The attacker can then replace this code with their own executable code, which can drastically change the program’s behavior.
For example, if the overwritten part of memory contains a pointer (an object that points to another location in memory), the attacker’s code could replace that code with another pointer that points to an exploit payload. This can transfer control of the entire program to the attacker’s code.
Who is vulnerable to buffer overflow attacks?
Some coding languages are more susceptible to buffer overflow than others. C and C++ are two popular languages with high vulnerability, as they do not contain built-in protections against accessing or overwriting data in their memory. Windows, Mac OSX, and Linux contain code written in one or both of these languages.
More modern languages, such as Java, PERL, and C#, have built-in features that help reduce the chances of buffer overflow, but they cannot prevent it entirely.
How to protect yourself from buffer overflow attacks
Fortunately, modern operating systems have runtime protections that help mitigate buffer overflow attacks. Let’s explore two common protections that help mitigate the risk of exploitation:
- Address space randomization – Randomly rearranges the address space locations of key data areas of a process. Buffer overflow attacks are generally based on knowing the exact location of important executable code; randomizing address spaces makes this nearly impossible.
- Data execution prevention: Marks certain areas of memory as executable or non-executable, preventing an exploit from executing code found in a non-executable area.
Software developers can also take precautions against buffer overflow vulnerabilities by writing in languages that have built-in protections or by using special security procedures in their code.
Despite precautions, developers continue to discover new buffer overflow vulnerabilities, sometimes after a successful exploit. When new vulnerabilities are discovered, engineers must patch the affected software and ensure that users of the software have access to the patch.
What are the different types of buffer overflow attacks?
There are a number of buffer overflow attacks that employ different strategies and target different parts of the code. Below are some of the most well-known.
- Stack overflow attack – This is the most common type of buffer overflow attack and involves overflowing a buffer in the call stack.
- Integer overflow attack – In an integer overflow, an arithmetic operation results in an integer (whole number) that is too large for the integer type intended to store it; this can result in a buffer overflow.
- Unicode overflow – A unicode overflow creates a buffer overflow by inserting unicode characters into an input that expects ASCII characters. (ASCII and unicode are encoding standards that allow computers to represent text. For example, the letter “a” is represented by the number 97 in ASCII. While ASCII codes only cover characters from Western languages, Unicode can create characters for almost every written language on the planet. Since there are many more characters available in Unicode, many of them are larger than the largest ASCII characters).
*Computers rely on two different models of memory allocation, known as the stack and the heap; both live in the computer’s RAM. The stack is well organized and maintains data in a “last in, first out” model. Any piece of data that was recently placed on the stack will be the first to come off, just as the last bullet inserted into an ammunition magazine will be the first to be fired. The heap is a disorganized collection of extra memory; data does not enter or leave the heap in any particular order. Since accessing memory from the stack is much faster than accessing it from the heap, the heap is generally reserved for larger data or data that a programmer wants to manage explicitly.
My final opinion on this method of attack.
It is a very complex and difficult method of attack to use.
Those who use this type of attack usually have an expert level of knowledge in C and C++ or have a whole team of people who know all the different ways to use these languages, as well as a very high level of knowledge of computer memory management (something that very few people have a high level of).
It is one of the most effective attacks, but at the same time extremely complex, which is why I have never delved deeply into this attack.
If you want to learn a little more and try it out, I recommend this guide:
It is quite comprehensive for use in Linux and ideal for a first encounter with this type of attack.
I hope you like this post.